Cool stuff in NIPS 2015 (symposium) - Neural Style
The deep learning algorithm, Neural style, is also known as neural art. Some similar algorithmic techniques have been seen in so called deep dream. It is a recent work in the filed of deep learning, and of course it’s super cool. The algorithm has been there for a few months already and I have noticed it for a while. Let’s take a close look at technology behind the scene.
Table of content
- Table of content
- Introduction
- Technology behind the scene
- Create your own neural style painting
- Criticisms
- More artworks
- Work in progress
Introduction
First off, what this clever algorithm does is to render an input image A with some visual experience learnt from another input image B to create a new image (e.g., shown on the very top of this post). This is known as photorealistic rendering. From a more technical point of view, the content of image A remains while the visual style switches to the one used in image B. The following pictures rendered by neural style are from the original technical paper in arxiv (although not very technical :relaxed:) where
- Image A is an image to be rendered by this algorithm.
- Image B is a rendered image using style of The Shipwreck of the Minotaur by J.M.W.Turner, 1805.
- Image C is a rendered image using style of The Starry Night by Vincent van Gogh, 1889.
- Image D is a rendered image using style of Der Schrei by Edvard Munch, 1893.
- Image E is a rendered image using style of Femme nue assise by Pablo Picasso, 1910.
- Image F is a rendered image using style of Composition VII by Wassily Kandinsky, 1913.
For instance, the style of Van Gogh’s The Starry Night looks to me peaceful, clear, and purified. It is with high contrast and also with clean color. Similar style has been added into image C. I don’t really understand any art. But Chinese readers can check this Zhihu page to find out why Vincent Van Gogh’s art is super good.

Technology behind the scene
I guess everything starts from the observation that very deep neural network demonstrates near-human performance in the area of visual perception such as object and face recognition, sometimes the performance is even better that human competitors (a lot of reference papers should be listed here in order to make this claim, however I was a bit loose here as this is merely a blog post). On the other hand, human has unique skill of creating a variety of visual experiences by playing around content and style of an arbitrary image. Then the question is really to understand how human create and perceive autistics? Or from another perspective, how to algorithmically create a piece of art by combining style and content. The short answer is through a technology driven by Convolutional Neural Network (CNN).
The key finding of this work is that the representations of content information and style information in the CNN are separable. In particular, the algorithm is able to model the content and style independently.
Content representation
CNN is a feed forward neural network in which each layer can be seen as a collection of image filters. Each filter extracts a certain feature from the input image. The output of each layer is a collection of feature maps composed by different filters. As a result, the input image is transformed into a series of transformations along the processing hierarchy that increasingly care about the actual content of the image rather than exact pixel values. One can reconstruct the origin image from each layer in which lower level layers will reproduce the original pixels while the high level ones will output contextual information. It is not difficult to see that it is relative easy to reproduce the original image from low level layers. In addition, we see that the context of the image can be captured by high level layers.
Style representation
The style of an image is a bit tricky to capture. But remember we have a collection of feature maps in each layer of the deep neural network. The style feature is built on top of the content features. In particular, it consists of correlations between different context features. Thus, we end up with style features in multiple layers and have a stationary, multiple level style representation of the input image.
Put together
Put together content representation and style representation, we end up with a deep neural network model shown in the following picture (picture taken from the original technical paper).
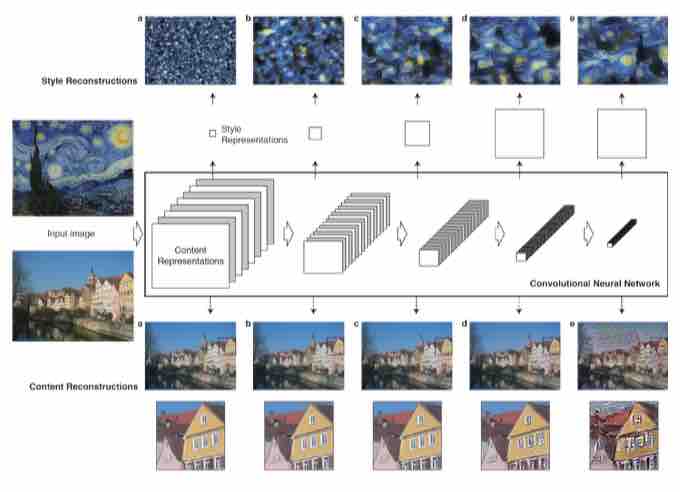
An input image is represented as a collection of filtered images in each layer of the neural network while the number of filtered image increases along the hierarchy of the network. The granularity of the content feature decrease along the hierarchy of the network in which high level layer captures more about content than the detailed pixel values.
On the top of the original CNN representation, there is a new feature space capturing the style information of the image. The style feature computes the correlation between different content features of each layer of the neural network. This features focus more on the details of the image and less on the global arrangement of the pixels when going deeper along the network hierarchy.
Rendering
Rendering is performed by finding an image that simultaneously matches the content representation of the first image and the style representation of the second image (a classical piece of art). However, one might notice that the content and the style information of an image might not be perfectly separated. Therefore, the algorithm aims to minimize a cost function which contains two terms at the same time. Details can be found from the original technical paper.
Create your own neural style painting
Deep dream web application
There is web service implementing a similar algorithm (possibly?), sometimes known as deep dream. The online platform allows you to upload an image and render it with a default style. Follow this link in order to access the deep dream. I might be wrong about deep dream as I haven’t yet check the original paper.
DeepForger twitter bot
Deep dream might be the most easies way to render an image using a similar algorithm and technology. However, it is not possible to render an image based on a arbitrary style given by another input. DeepForger twitter bot is a valuable alternative. Follow this link to access this robot.
What you need to do is just to send the robot two images, one is the image you want to render and the other is the image you want to use as the style. It is an extremely convenient way of create neural style especially when you are not in a big hurry or you don’t have a linux machine. However, if you need to render a collection of images quickly and in a much more flexible way, you might want to continue with this blog post to set up a standalone deep style machine running locally on your own computer.
Standalone implementation
A simple google search will give you many implementation of the same algorithm, for example
Installation
I will be using the neural-artistic-style as this is relatively easier to install and to run.
In particular, it should work out with the following steps
- Download the algorithm implementation from Github with
git clone git@github.com:andersbll/neural_artistic_style.git. - Install
CUDAarrypackage link in Github. - Install
deeppypackage link in Github. - There might be some obstacles during the installation of these two packages (at least in my case). Just be patient and install all Python package dependencies (e.g.,
Pillow,PIL,JPEG) and you will be fine.
Run
Run the algorithm with the following command python neural_artistic_style.py --subject images/tuebingen.jpg --style images/starry_night.jpg. Unfortunately, this is very slow in my case with CPU.
Criticisms
Philosophically, I would argue that it is merely an advanced image filter than artificial intelligent. The way I see this deep learning algorithm is just two levels of representation, one for content modeled by CNN and another for style modeled by correlation. Therefore, it will never produce any new contents or styles. On the other hand, some people do think this algorithm is essentially producing art or a mixture of original content and new style :laughing: All right, anyway, the definition of art is very vague and you will never be able to tell yes from no :laughing:
Technically, I would argue that algorithm is not computationally efficient for large-scale commercial use. Also, if you don’t have computational power of GPUs and running this algorithm on CPUs, it will be terribly slow. Besides, the algorithm does not tell the difference between portrait images and natural sceneries. This will be rather problematic in a way that the algorithm does not have any knowledge about human face which is somehow important in portrait rendering.
More artworks
Look at a portrait image being rendered by different art styles.






Work in progress
Currently I am working in progress to build a wep service with APIs by running this deep algorithm in the cloud (e.g. Amazone AWS, AliCloud). Let’s see what I can achieve after sometime.
Hongyu Su 05 January 2016 Helsinki